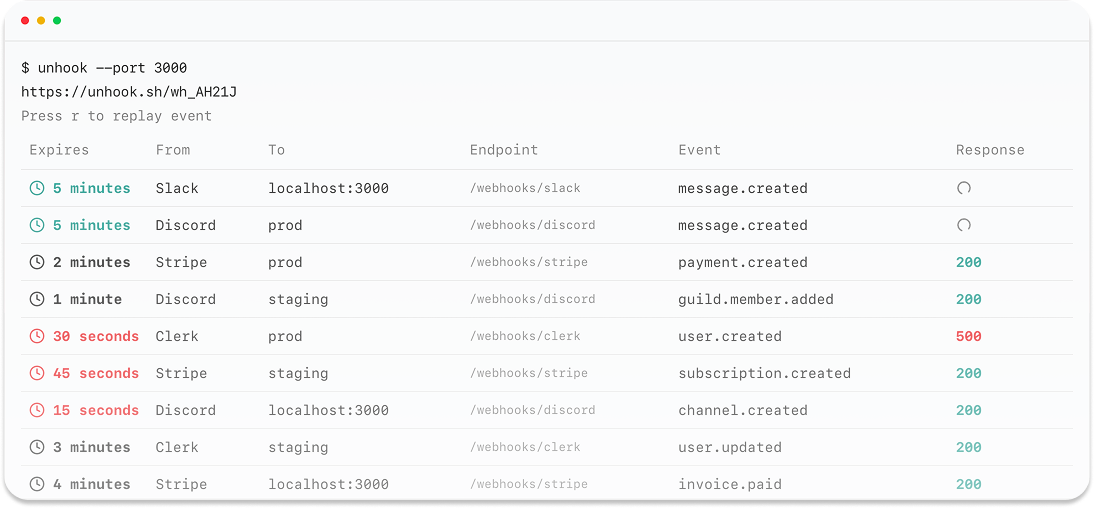
Overview
The Untrace Python SDK provides zero-latency LLM observability with automatic instrumentation for all major LLM providers. Built on OpenTelemetry standards, it captures comprehensive trace data and routes it to your chosen observability platforms.Quick Start
Start tracing LLM calls in minutes
Framework Support
FastAPI, Django, Flask, and more
Async Support
Full async/await support
Examples
Real-world examples and best practices
Installation
Install the Untrace Python SDK using pip:Quick Start
Basic Setup
Synchronous Usage
Configuration
Client Options
Environment Variables
The SDK supports configuration via environment variables:Framework Integration
FastAPI
Django
Flask
Celery Integration
Advanced Usage
Custom Trace Attributes
Batch Tracing
Error Handling
Context Managers
Decorators
The Python SDK provides decorators for easy instrumentation:Examples
OpenAI Integration
LangChain Integration
Async Generator Support
Best Practices
1. Use Context Managers
2. Handle Errors Gracefully
3. Use Batch Operations for High Volume
4. Set Appropriate Timeouts
Troubleshooting
Common Issues
No traces appearing
No traces appearing
Connection timeouts
Connection timeouts
Memory usage
Memory usage
Async/await issues
Async/await issues
API Reference
UntraceClient
The main client class for interacting with the Untrace API.Constructor
Methods
trace(event_type, data, metadata=None): Send a trace event (async)trace_sync(event_type, data, metadata=None): Send a trace event (sync)trace_batch(traces): Send multiple traces in batch (async)update_trace(trace_id, data): Update an existing trace (async)get_trace(trace_id): Retrieve a trace by ID (async)close(): Close the HTTP client
Exception Types
UntraceError: Base exception for all SDK errorsUntraceAPIError: Raised when API requests failUntraceValidationError: Raised when request validation failsUntraceTimeoutError: Raised when requests timeout
Migration Guide
From Other Observability Tools
Support
- Documentation: https://docs.untrace.dev
- GitHub Issues: https://github.com/untrace-dev/untrace/issues
- Discord Community: Join our Discord
- Email Support: support@untrace.dev
Next Steps
Dashboard Guide
Learn to use the Untrace dashboard
Configuration
Configure your observability setup
Examples
Browse Python example implementations
API Reference
Complete API documentation