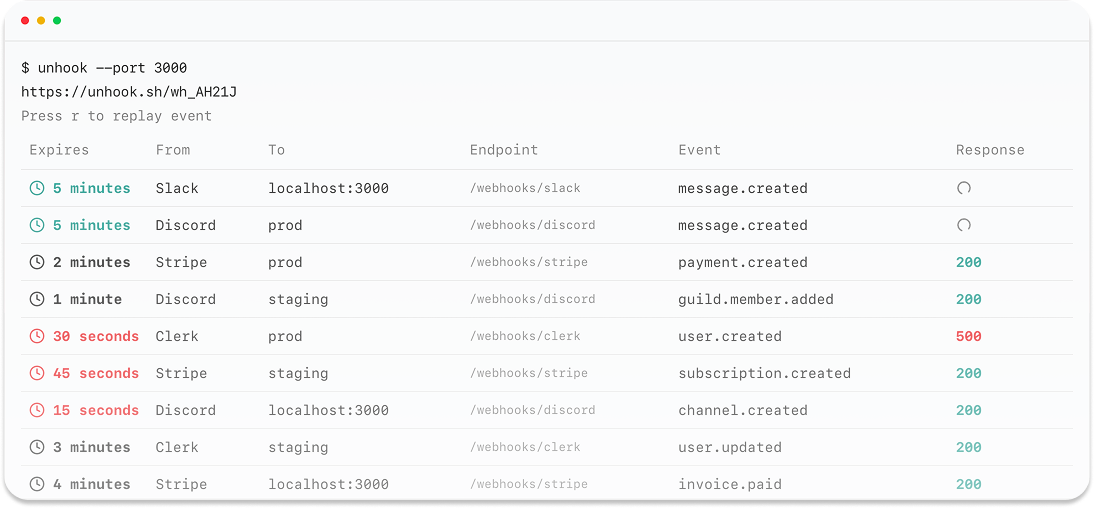
Overview
The Untrace SDK provides zero-latency LLM observability with automatic instrumentation for all major LLM providers. Built on OpenTelemetry standards, it captures comprehensive trace data and routes it to your chosen observability platforms.Supported Languages
Untrace provides native SDKs for all major programming languages:JavaScript/TypeScript
Node.js, React, Next.js, Express, and more
Python
FastAPI, Django, Flask, and async frameworks
Go
Gin, Echo, Fiber, and microservices
Rust
Axum, Actix, Tokio, and high-performance apps
C#/.NET
ASP.NET Core, Console apps, and services
Elixir
Phoenix, LiveView, and OTP applications
New to Untrace? Check out our SDK Overview to compare all available languages and choose the best fit for your project.
Quick Start
Start tracing LLM calls in minutes
Auto-instrumentation
Automatic tracing for popular LLM libraries
Type Safety
Full TypeScript support with type definitions
Examples
Real-world examples and best practices
JavaScript/TypeScript
Installation
Install the Untrace SDK using your preferred package manager:Quick Start
Basic Setup
Manual Instrumentation
Configuration
SDK Options
Environment Variables
The SDK supports configuration via environment variables:Auto-instrumentation
Supported Providers
The SDK automatically instruments these LLM providers:AI/LLM Providers
- ✅ OpenAI - GPT-4, GPT-3.5, Embeddings, DALL-E
- ✅ Anthropic - Claude 3, Claude 2
- ✅ Google AI - Gemini Pro, PaLM
- ✅ Mistral - Large, Medium, Small models
- ✅ Cohere - Command, Embed, Rerank
- ✅ AWS Bedrock - All supported models
- ✅ Azure OpenAI - Enterprise deployments
- ✅ Together.ai - Open source models
- ✅ Replicate - Model marketplace
- ✅ Hugging Face - Inference API
Framework Support
- ✅ LangChain - Chains, agents, tools
- ✅ LlamaIndex - Data frameworks
- ✅ Vercel AI SDK - Edge-ready AI
How It Works
Decorators
The SDK provides powerful decorators for clean instrumentation:@trace
Create spans for any method:@llmOperation
Specialized decorator for LLM operations:@metric
Record custom metrics:Manual Tracing
Creating Spans
Context Propagation
TypeScript Support
Type-Safe Provider Instrumentation
Custom Span Types
Observability Features
Token Usage Tracking
The SDK automatically captures token usage:Cost Calculation
Error Tracking
Advanced Features
Workflow Tracking
Track complex LLM workflows:Sampling Strategies
Reduce costs with intelligent sampling:PII Redaction
Automatic PII detection and redaction:Framework Examples
Next.js App Router
Express.js
LangChain Integration
LlamaIndex Integration
Metrics and Monitoring
Custom Metrics
Performance Monitoring
Best Practices
1. Initialize Early
2. Use Semantic Attributes
3. Handle Sensitive Data
4. Implement Error Boundaries
Troubleshooting
Common Issues
No traces appearing
No traces appearing
Missing auto-instrumentation
Missing auto-instrumentation
- Ensure SDK is initialized before importing LLM libraries
- Check that the provider is supported
- Try manual instrumentation as a fallback
High latency
High latency
Memory usage
Memory usage
Debug Mode
Enable comprehensive debugging:API Reference
Core Functions
Instrumentation
Utilities
Migration Guide
From OpenTelemetry
From Other Observability Tools
Python
Installation
Quick Start
Synchronous Usage
Framework Integration
FastAPI
Django
Go
Installation
Quick Start
Gin Framework
Rust
Installation
Add this to yourCargo.toml:
Quick Start
Axum Framework
C#/.NET
Installation
Quick Start
ASP.NET Core
Elixir
Installation
Adduntrace_sdk to your list of dependencies in mix.exs:
Quick Start
Phoenix Framework
Support
- Documentation: https://docs.untrace.dev
- GitHub Issues: https://github.com/untrace-dev/untrace/issues
- Discord Community: Join our Discord
- Email Support: support@untrace.dev
Next Steps
Dashboard Guide
Learn to use the Untrace dashboard
Routing Rules
Configure intelligent trace routing
Provider Setup
Connect to LLM providers
Examples
Browse example implementations